Schlagwortvergabe und RAG-Chatbot für die Parlamentsbibliothek
Im Rahmen eines Forschungsauftrages erarbeiten wir eine Applikation welche Parlamentsgeschäfte mithilfe eines RAG-Chatbots besser auffindbar machen soll. Zusätzlich wird untersucht, ob Geschäfte automatisch klassifiziert werden können.
Steckbrief
- Beteiligte Departemente Wirtschaft
- Institut(e) Institut Public Sector Transformation (IPST)
- Forschungseinheit(en) Digital Sustainability Lab
- Strategisches Themenfeld Themenfeld Humane Digitale Transformation
- Laufzeit (geplant) 01.04.2024 - 31.10.2024
- Projektleitung Prof. Dr. Marcel Gygli
-
Projektmitarbeitende
Siddhartha Singh
Veton Matoshi - Partner Parlamentsbibliothek
- Schlüsselwörter RAG, Topic Modell, Chatbot, Parlamentsbibliothek
Ausgangslage
Die Parlamentsbibliothek ist für die Verwaltung der Geschäfte auf der offiziellen Geschäftsplattform Curia Vista zuständig. Bei der Erfassung müssen zu jedem neuen Geschäft mehrere Themengebiete erfasst werden. Ein Schritt welcher aktuell voll manuell gemacht wird. Basierend auf diesen Daten müssen Parlamentsbibliothekar*innen auch Anfragen von Parlamentarier*innen beantworten (z.B. "Wieviele Geschäfte zum Thema Steuerhinterziehung gab es in den letzten 5 Jahren"). Dies mit Suchsystemen die nur stichwortbasiert funktionieren und daher nur begrenzte Möglichkeiten haben um relevanten Kontext mit einzubeziehen.
Vorgehen
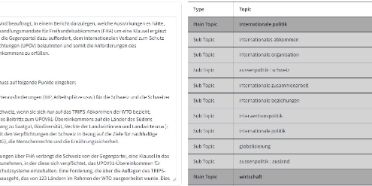
In unserer Arbeit untersuchen wir zwei Aspekte separat. Einerseits erstellen wir Modelle (sogenannte Topic Models) welche für neue Geschäfte automatisch ein oder mehrere Themengebiete vorschlagen. Diese Modelle erstellen wir basierend auf quelloffener Software. Die ersten Resultate dieser Arbeit sind auch bereits öffentlich einsehbar unter: https://huggingface.co/spaces/rcds/SwissParlTopicModelling In einem zweiten Schritt erarbeiten wir eine RAG-Chatbot basierte Applikation mithilfe derer Parlamentsbibliothekar*innen die Geschäfte durchsuchen können. Dazu können sie eine Frage mit natürlicher Sprache stellen und zusätzlich Suchkriterien basierend auf erfassten Metadaten erstellen. Basierend darauf werden dann relevante Geschäfte gesucht, falls gewünscht mithilfe eines Sprachmodelles zusammengefasst, und den Bibliothekar*innen zurückgegeben.